Benchmark Construction
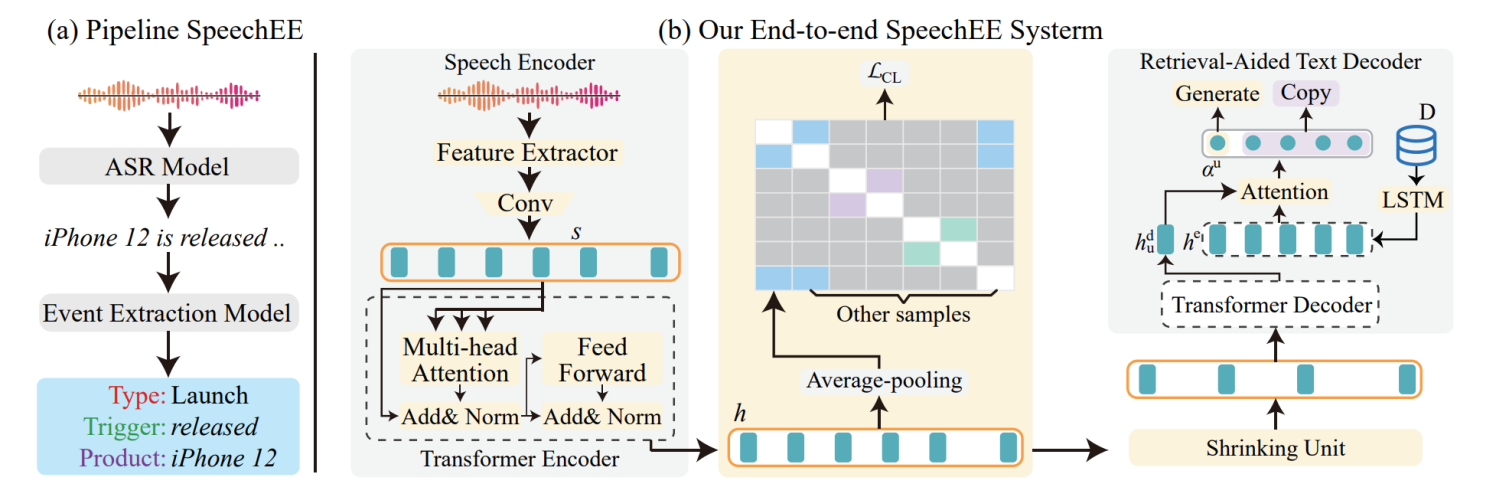
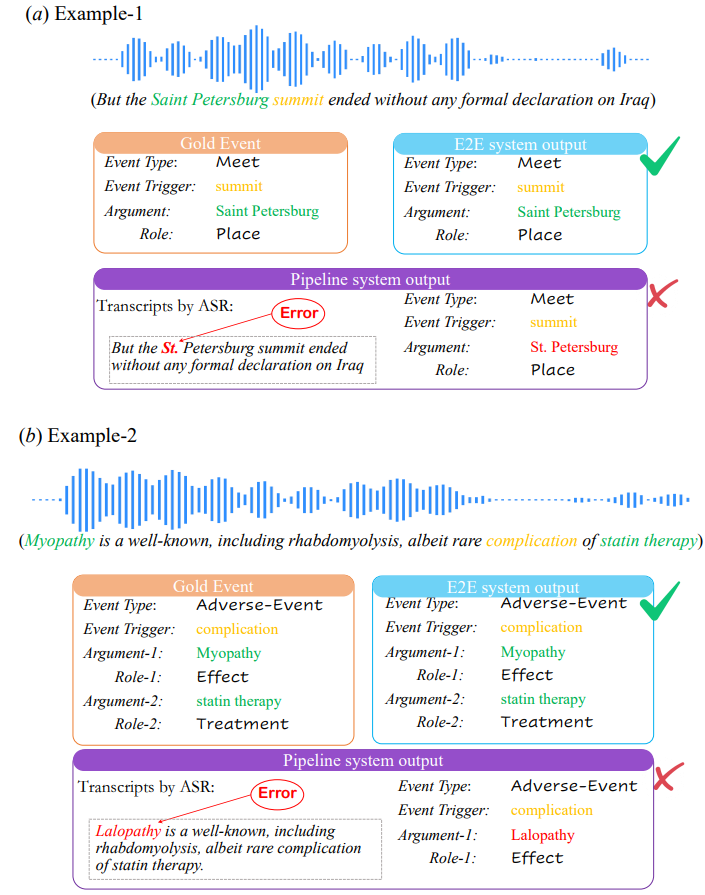
We proposed a novel large-scale benchmark dataset for the SpeechEE task, sourced from eight classical text event extraction datasets that are widely used and adhere to strict standards. The dataset was constructed through both manual recording and system synthesis methods, resulting in a large-scale, high-quality benchmark dataset that spans multiple scenarios, domains, languages, styles, and backgrounds, as illustrated in Figure 1.
- Multiple Scenarios: The dataset includes sentence-level event extraction, document-level event extraction, and dialogue-level event extraction, covering three different task scenarios.
- Multiple Domains: The data spans various fields, including news, medicine, cybersecurity, bioscience, and film.
- Multiple Languages: It involves two languages, with six English subsets and two Chinese subsets.
- Multiple Styles: It features a variety of speaker styles, including different ages, genders, voice tones, and intonations.
- Multiple Backgrounds: The speech settings include not only quiet environments but also ten different noise backgrounds to better simulate real-world speech event extraction scenarios.
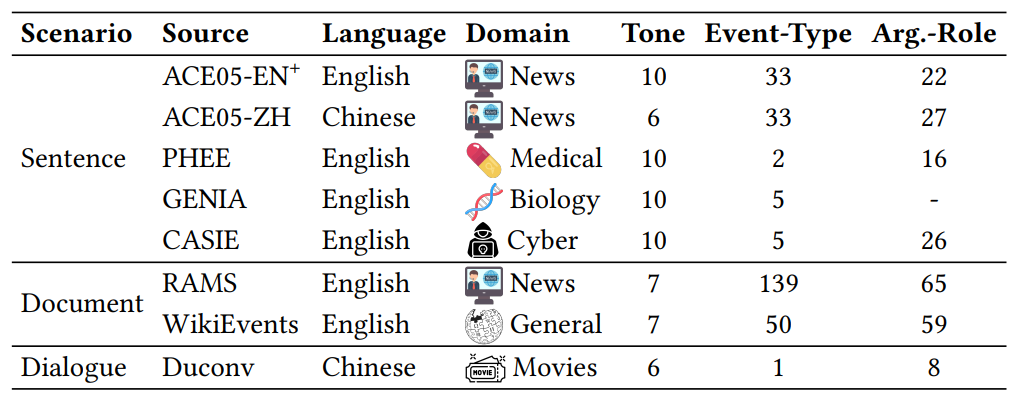
Figure 1: Key characteristics of our SpeechEE dataset.
Due to the strict environmental requirements and high costs associated with manually recording speech data, we supplemented the manually recorded speech dataset by leveraging existing high-quality open-source Text-to-Speech (TTS) frameworks, such as Bark and edge-tts, to augment the training data. This approach involved synthesizing speech data based on textual event extraction datasets. Finally, the manually recorded and system-synthesized speech data underwent post-processing screening and cross-validation to ensure strict quality control. As a result, a large-scale SpeechEE benchmark dataset was created, as shown in Figure 2. This benchmark dataset provides robust support for evaluating the performance of SpeechEE models.
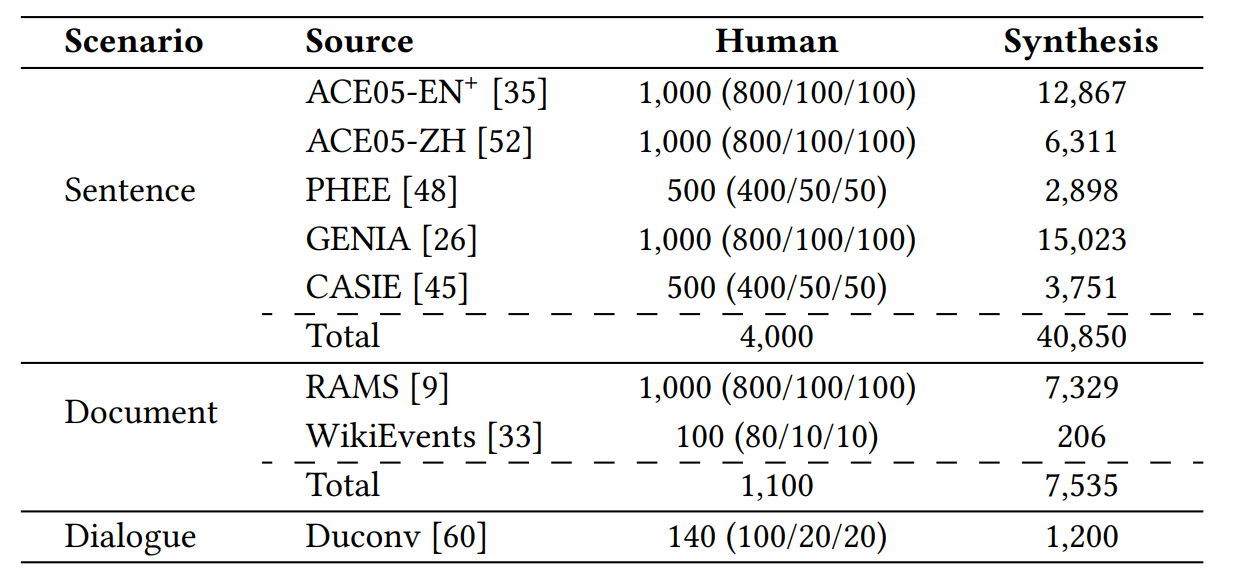
Figure 2: Statistics of the SpeechEE dataset. In the brackets are the splits of train/develop/test sets.